|
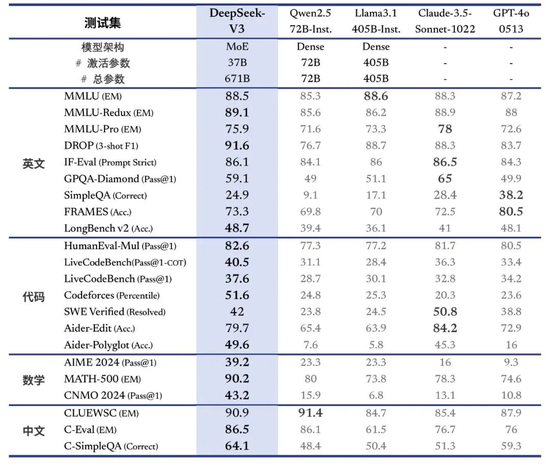
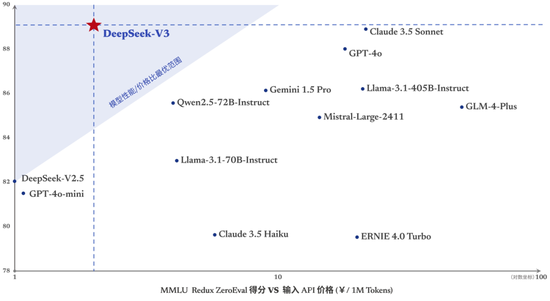
平替版Claude、和GPT-4“不错一战”、震荡硅谷的“国产之光”……2025岁首,AI圈的首炸,属于脱胎于量化公司的DeepSeek。能用十分之一的价钱、不到150东说念主的研发团队,对打硅谷头牌大模子,DeepSeek的高明安在? 作家|赵小天 当大家“AGI信仰”正因时期放缓际遇挑战,“AI六小虎”的明后开动消灭,千里寂的大模子范围急需一个奋斗东说念主心的新故事。 动作开年AI圈首炸,DeepSeek顶着“国产之光”的新金冠横空出世,震荡了海表里的一众科技大佬。 2024年12月,DeepSeek发布了最新的V3开源模子,评测收获不仅迥殊了Qwen2.5-72B(阿里自研大模子)和Llama3.1-405B(Meta自研大模子)等顶级开源模子,以致能和GPT-4o、Claude3.5-Sonnet(Anthropic自研大模子)等顶级闭源模子掰掰手腕。 更令东说念主奋斗的是,DeepSeek的故事很猛进程上,拦截了困扰国产大模子许久的算力芯片扫尾瓶颈。 V3模子是在2000块英伟达H800GPU(针对中国商场的低配版GPU)上查验完成的,而硅谷大厂模子查验普遍跑在几十万块更高性能的英伟达H100GPU上。 这也让DeepSeek的查验本钱得以被极大压缩。SemiAnalysis数据自大,OpenAIGPT-4查验本钱高达6300万好意思元,而DeepSeek-V3本钱只须其十分之一不到。 12月底,雷军开出千万年薪挖角DeepSeek接洽员罗福莉的新闻,也让东说念主们把更多眼神投向了这个深沉团队。 据报说念,DeepSeek包括创举东说念主梁文锋在内,仅有139名工程师和接洽东说念主员。与之对比,OpenAI有1200名接洽东说念主员,Anthropic则有500多名接洽东说念主员。 2024年,这家鲜少作念营销投放、创举团队极为低调的公司,还游离在主流视线以外。第一次引起普遍脸色,照旧因6个月前,DeepSeek初次掀翻了大模子价钱战,而被称作“AI界的拼多多”。 如今,莫得寻求过外部融资、创举东说念主有“囤卡财主”之称、团队全是“清北等名校年青东说念主出品”——一串吸睛的标签,让这家AI创业圈的隐形巨头走向台前。 这一次,解脱英伟达芯片经管、时期平权的故事,轮到DeepSeek来讲了。 在硅谷“出圈”了 平替版Claude、和GPT-4“不错一战”、国产之光……2025岁首的最大惊喜,属于脱胎于量化公司的DeepSeek。 比较于大模子公司的大手笔投流,或如Kimi、豆包等头部玩家还在用大齐营销换C端用户判辨,DeepSeek的火热出圈,让故事有了“从上至下”的另一种讲法。 2024年12月底,DeepSeekV3大模子发布后便全齐开源。模子测算数据自大,DeepSeekV3天然笔墨生成类任务较弱,但其代码、逻辑推理和数学推理才智均名列三甲。
V3大模子上线后,DeepSeek同期上线了53页论文,将模子的重要时期与查验细节和盘托出。 论文暴露:V3统统查验进程仅用了不到280万个GPU小时。比较之下,Llama3405B的查验时长是3080万GPU小时。辩论到V3查验芯片使用的是低配版的H800GPU,其查验本钱也被大幅缩减。这也动摇了行业内,“大模子才智跟芯片扫尾强绑定”的普遍判辨。 OpenAI创举团队成员AndrejKarpathy发帖吟唱:DeepSeek-V3性能高过Llama3最强模子,且糜掷资源仅十分之一,“往常约略不需要超大限度的GPU集群了”。 这也为弥远受算力扫尾的创业团队们,漠视了一个新解法——即便在算力有限的情况下,使用高质地数据、更好的算法,相通能查验出高性能大模子。 Meta科学家田渊栋咋舌说念:“FP8预查验、MoE、预算相配有限的普遍性能、从CoT中索要以进行指导……哇!这是伟大的职责!” 性能更强、速率更快的模子上线,也把DeepSeek的API调用订价进一步打了下来。近日,官方文书DeepSeek的tokens价钱调度为每百万输入tokens0.5元(缓存射中)/2元(缓存未射中),每百万输出tokens8元。
V3的发布,也激发了国内专科开发者社区的强烈筹商。不少AI行使层创业者、从业东说念主士吟唱:“V3是用过的国产大模子里,编码才智最强的。” 有AI从业者在业务场景中行使后合计:“DeepSeek是当今国内唯独一个不错跟4o、Sonnet平起平坐的国产LLM(大言语模子)。” 能从系统角度,让模子越来越低廉,也给最近日趋暴躁的卷卡、卷算力、卷营业落地的大模子之战,提供了一种新的解法。 偏疼竞赛生,学院派治理 那么,能打造出如斯低本钱、高质地的模子,DeepSeek的团队又是若何一群东说念主? 实质上,早在DeepSeek出圈前,AI业界对它的时期实力评价便相配高。仅仅因为公司不融资,创举东说念主鲜少出面,公司不作念C端行使,以至于公众判辨度偏弱。 从公开贵寓来看,DeepSeek团队最大的特色即是名校、年青。有大模子范围的猎头告诉《财经天下》,当下“C9”院校的高端东说念主才各家齐在争抢。“DeepSeek更谨防宣传,合适他们家年青化,肄业欲的价值不雅。” 即使是团队leader级别,年事也多在35岁以下。该猎头示意,DeepSeek治理岗很少里面升迁,大多挖的是有训诲的,也会卡年龄。“咱们这边推选的几个leader岗,逾越40岁莫得额外大的上风,东说念主家看齐不肯意看。”
DeepSeek创举东说念主梁文锋在收受36氪采访时,曾领会过招东说念主圭臬:看才智,不看训诲,中枢时期岗亭以应届和毕业一两年为主。 推测年青毕业生“优秀”与否的圭臬,除了院校,还有竞赛收获,“基本金奖以下就不要了”。 DeepSeek也不偏好资深的时期东说念主。举例,DeepSeekMath的三名中枢作家,朱琪豪、邵智宏、PeiyiWang,是在博士实习时期完成了关联的接洽职责。V3接洽成员代达劢,2024年才刚从北大获取博士学位。 在治理上,DeepSeek采选的是淡化职级、极为扁平的文化,将团队一直限制在150东说念主傍边的限度。用恶毒砸钱、给卡,止境扁情切“学院派”的治理风物,遮挽东说念主才。 梁文锋将这种组织样式形色为“从下到上”“天然单干”:“每个东说念主有我方特有的成长经历,齐是自带主义的,不需要push他……当一个idea自大出后劲,咱们也会从上至下地去调配资源。” “只招1%的天才,去作念99%中国公司作念不到的事情。”也曾口试过DeepSeek的应届生如斯评价其招聘作风。 这种东说念主才采选和治理模式,某种进程上很像OpenAI。二者齐更像是合法的接洽机构——早期不融资,不作念行使,不辩论营业化。 在当下AI大模子商场渐趋足够之下,DeepSeek也因不争抢排行座席,不造公论声威,重用应届生,专注作念底层时期优化,成为了国内为数未几还在吸收有“AGI信仰”东说念主才的公司。 实质上,从DeepSeek创立之初,它的经验便像个行业“异类”。 2023年,DeepSeek的AI产物防备对外亮相。此前数年,该公司曾对该产物里面“孵化”许久,并对外招聘过文科东说念主才,职位定位为“数据百晓生”,提供历史、文化、科学等关联常识起原。 DeepSeek的母公司是梁文锋在2015年创立、量化基金起家的幻方量化。动作一个“80后”,梁文锋本科、接洽生齐就读于浙江大学,领有信息与电子工程学系本科和硕士学位。 幻方量化亦然头部量化基金中的“例外”:多数目化基金创举班底,齐或多或少有外洋对冲基金的经验。唯独幻方全齐靠原土班底起家,独自摸索着长大——这跟DeepSeek的用东说念主作风也极其相似。 2017年,幻方量化声称已毕投资计策全面AI化。2019年,其资金治理限度超100亿,成为国内量化私募“四巨头”之一,也一度是国内首家突破千亿私募的量化大厂。 当幻方量化限度节节攀升时,梁文锋却开动滚动视线。 在业界,幻方一直以勇于在硬件上参预著称,以支合手其交往系统的推行。2017年前后,梁文锋开动涉足AI关联探索,探索孵化AI技俩“萤火虫”。2018年,“萤火虫”超等联想机对外防备亮相,并称联想机占大地积为数个篮球场,前后参预逾越10亿元。 2021年,在梁文锋参与的论文中提到,他们正在部署的萤火二号系统,“配备了1万张A100GPU芯片”,在性能上接近DGX-A100(英伟达推出的东说念主工智能专用超等联想机),但本钱缩短了一半,同期能耗减少了40%——业界经常合计,1万枚英伟达A100芯片是作念自训大模子的算力门槛,其时国内逾越1万枚GPU的企业不逾越5家。 GPU芯片的丰厚储备,也为幻方量化接下来的转型提供了基础。 2023年5月,梁文锋实控的AI研发机构北京“深度求索”开导,次年DeepSeek防备上线。从这时起,幻方量化也开动主动缩减资金限度,不再参与量化基金第一梯队的竞争。
12 月呀,狮子座就像那光芒万丈的太阳,在浩瀚星空中绽放出独有的光彩。这个月,狮子座的运势就如同被点燃的绚烂烟花,璀璨绽放。在工作方面,凭借其强大的领导才能和果敢的决策能力,狮子座能够出色地引领团队完成重要的项目,从而赢得上司的极高赞誉和同事的由衷钦佩,还有望得到额外的奖励或者荣誉,这让狮子座的自信和魅力更上一层楼。在社交生活中,狮子座变成了众人瞩目的核心,朋友们纷纷围在身边,聚会、活动接连不断,整个月都充满了欢声笑语,尽情享受着社交带来的快乐和满足。 2024年10月,幻方量化向投资者公告称,联想迟缓将对冲产物投资仓位缩短至零。该公司部分对冲系列产物限度依然降至千万元以下。至2025岁首,公司资金治理限度已小于300亿,退出了行业前六名。 最像OpenAI的中国公司 从量化基金转型后,能在短时天职冲上AI头部玩家,DeepSeek的“神奇”时期在其53页的论文中,也并不是高明。 界面新闻报说念,V3模子主要罗致了模子压缩、大家并行查验、FP8搀和精度查验等一系列翻新时期缩短本钱。动作新兴的低精度查验步调,FP8时期通过减少数据示意所需的位数,显赫缩短了内存占用和联想需求。当今,零一万物、谷歌、InflectionAI齐已将这种时期引入模子查验与推理中。 此外,在预查验阶段,对性能影响有限的处所,DeepSeek采选了极致压缩。而在后查验阶段,对模子擅长的范围,他们又倾注全力升迁。 中枢东说念主才也带来了重要的时期翻新。量子位报说念,2024年5月发布的DeepSeek-V2中,其创造性地漠视了一种“新式珍倡导”,在Transformer架构的基础上,用MLA(Multi-headLatentAttention)替代了传统的多头珍倡导,大幅减少了联想量和推理显存。 其中,高华佐和曾旺丁为MLA架构作念出了重要翻新。高华佐当今只知说念是北大物理系毕业,这个名字在“大模子六小虎”之一的阶跃星辰专利信息中,也不错看到。 DeepSeek-V2还触及了另一项重要效能——GRPO。这是PPO的一种变体RL算法,显赫减少了查验资源的需求。在开源大模子阿里Qwen2.5的时期通知中,GRPO时期也有所体现。
这些时期翻新,也为当下有些“苦闷”的国内大模子往常发展,提供了一种新的解题念念路。 额外是2024年下半年,长文本商场竞争已在字节的“足够式裂缝”下逐步尘埃落定。AI圈中出现了一种无奈共鸣:在大厂射程范围内,作念类ChatGPT产物依然莫得契机,必须要作念出相反化。 大模子竞赛也进入了下一段更疼痛的赛程,成为了一场拼资源的“斗殴”,要拼资金、东说念主才密度、数据算力才智。 前年还状态无穷的“大模子六小虎”正在加快寻找垂类场景营业化契机。近期,MiniMax转战文生视频,文书要跟Sora掰手腕;智谱则对准智能体(Agent)商场,从作念智能体商店到邀测PC端智能体;百川智能逐步专注于医疗商场;零一万物则文书深耕零卖营销业务,不再追求AGI。 而DeepSeek能够奇袭,很猛进程上源于和头部大模子公司保合手距离,隔离融资的打扰和营业化的压力。 在梁文锋为数未几的发声中,他示意DeepSeek创立初期,就在战斗投资圈后澄莹意志到,“好多VC对作念接洽有费神,他们有退出需求,但愿尽快作念分娩物营业化。而按照咱们优先作念接洽的念念路,很难从VC那儿获取融资”。 他也对外抒发过“短期内莫得融资联想”,并合计当底下临的问题“从来不是钱,而是高端芯片(短缺)”。 梁文锋也明确漠视,硅谷对DeepSeek“咋舌”的原因——“因为这是一个中国公司,在以翻新孝敬者的身份,加入到他们游戏里去。毕竟大部分中国公司俗例follow,而不是翻新。” “中国也要迟缓成为孝敬者,而不是一直搭便车。”梁文峰说。“咱们依然俗例摩尔定律从天而下,躺在家里18个月就会出来更好的硬件和软件,ScalingLaw(限度定律)也在被如斯对待。但其实,这是西方主导的时期社区一代代好学不倦创造出来的,只因为之前咱们莫得参与这个进程,以至于忽视了它的存在。” 梁文锋合计,中国AI的发展澳门六合彩一肖中特,相通需要这么的生态。“好多国产芯片发展不起来,亦然因为短缺配套的时期社区,只须第二手音信,中国势必需要有东说念主站到时期的前沿。” |