香港六合彩开奖结果统计 影驰GeFroce RTX 5090 D大将评测: DLSS 4助力, 4K高刷畅玩光追游戏
NVIDIA的Ada Lovelace架构RTX 40系显卡是在2022年10月推出了,当今一眨眼两年多畴昔了香港六合彩开奖结果统计,全新的Blackwell架构GPU将接替他们的位置,在CES 2025上NVIDIA拿出了首批RTX 50系显卡,包括为RTX 5090、RTX 5080、RTX 5070 Ti、RTX 5070、以及合规版RTX 5090 D,国内首发的是天然是RTX 5090 D,它与此前的RTX 4090 D径直削CUDA数目不同,RTX 5090和RTX 5090 D的硬件规格是一样的,仅仅RTX 5090 D的AI性能被限度了。

动作NVIDIA的中枢妥协伙伴,影驰也第一时刻推出了GeForce RTX 5090 D大将这款显卡,天然他们后续还会有更多的RTX 5090 D新品,星曜系列年后回来猜测就会和民众碰面。
GeForce RTX 5090 D简介
GeForce RTX 5090 D搭载的是GB202,与RTX 4090 D的AD102比拟,芯单方面积更大,从608mm²增至750mm²,晶体管数目也从763亿个加多至922亿个。GB202和AD102的晶体管密度分别为122.9MTr/mm²和124.9MTr/mm²,可见在制造工艺上两者相当接近。

完整的GB202 GPU包括12个GPC、96个TPC、192个SM、以及1个带有16个32位内存胁制器的512位内存接口,共有24576个CUDA中枢、192个第四代RT Core和768个第五代Tensor Core、以及768个纹理单位。
如果与AD102作念比较,会发现GB202在结构上有一些不同:一样是12个GPC,然则每个GPC里的TPC和SM数目增多了,TPC从6个增至8个,SM从12个增至16个;显存位宽也从384-bit增至512-bit,加上收受了新一代的GDDR7,带宽彰着增大;NVENC与NVDEC从3+3组合形成了4+4;另外还新增了AI Management Processor。

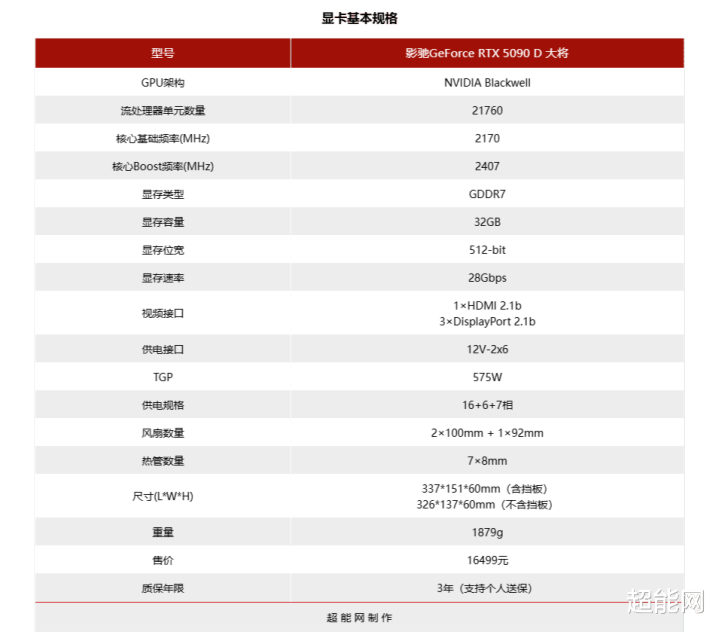
与过往一样,即等于顶级型号也莫得启用全部的中枢,RTX 5090 D作念了一些削减,CUDA中枢数目为21760个,比拟RTX 4090 D的14592个CUDA中枢数目大幅度加多了约49%,基础频率和加速频率齐有所训斥,另外整卡功耗升迁至575W,比起蓝本的425W也有较大增长,接近了12V-2×6接口600W的极限。新一代旗舰显卡另外一个比较大的变化在于显存,将配备32GB的GDDR7,显存位宽也从384位升迁至512位,显存速率为28Gbps,显存带宽也从1008GB/s暴增至1790GB/s。
Ada Lovelace和之前的GPU架构上,在H.264和H.265视频中提供了对4:2:0色度采样的撑执,Blackwell架构则加多了编码妥协码4:2:2色度采样视频的智商,这将省俭CPU的包袱,加速创作速率。此次RTX 5090 D配有3个NVENC编码器(第9代)与2个NVDEC解码器(第6代),而RTX 4090 D领有的是2个NVENC编码器(第8代)和1个NVDEC解码器(第5代),无论数目和质料齐得到了升迁。
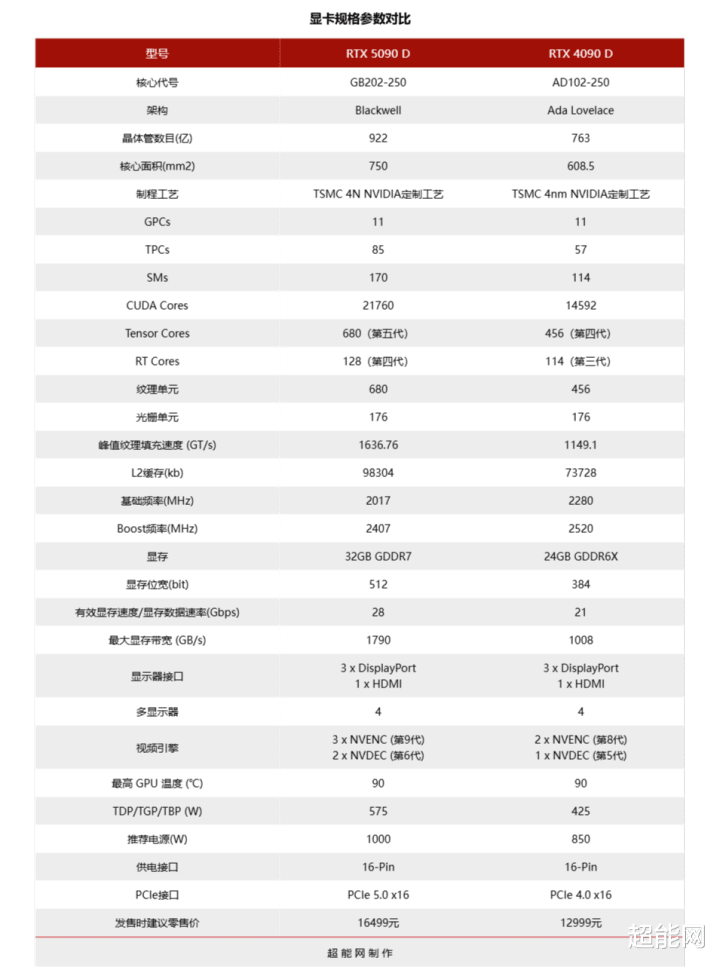
从上头的表格里可以看到,RTX 5090 D比拟RTX 4090 D在规格方面有了较大幅度的升迁,发售时官方提议零卖价(MSRP)也更高了,面向的是发热级DIY醉心者和PC游戏玩家。需要讲解少量,针对国内市集发售的RTX 5090 D与RTX 5090存在一些互异,惟一的区别是AI性能,从RTX 5090的3352 AI TOPS降至RTX 5090 D的2375 AI TOPS,训斥了约29%。
Blackwell架构明白
神经渲染引颈经营机图形学下一个期间
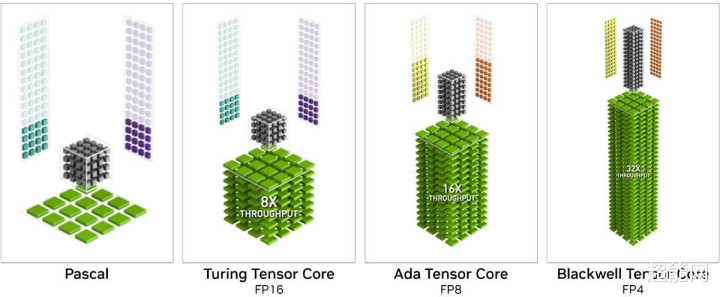
NVIDIA在Blackwell架构的新一代Tensor Core上,添加了对FP4浮点运算精度的撑执。FP4是一种较低的量化法子,雷同于文献压缩,可以减小模子推理经过中数据存储和经营量大小,提高经营效率,训斥该经过对显存的要求。
与大多量模子默许使用的FP16比拟,FP4使用的显存不到其一半,并使GeForce RTX 50系列GPU的性能比拟上一代升迁高达2倍。通落后骗NVIDIA TensorRT Model Optimizer提供的高档量化法子,这些增益简直不会影响输出质料。
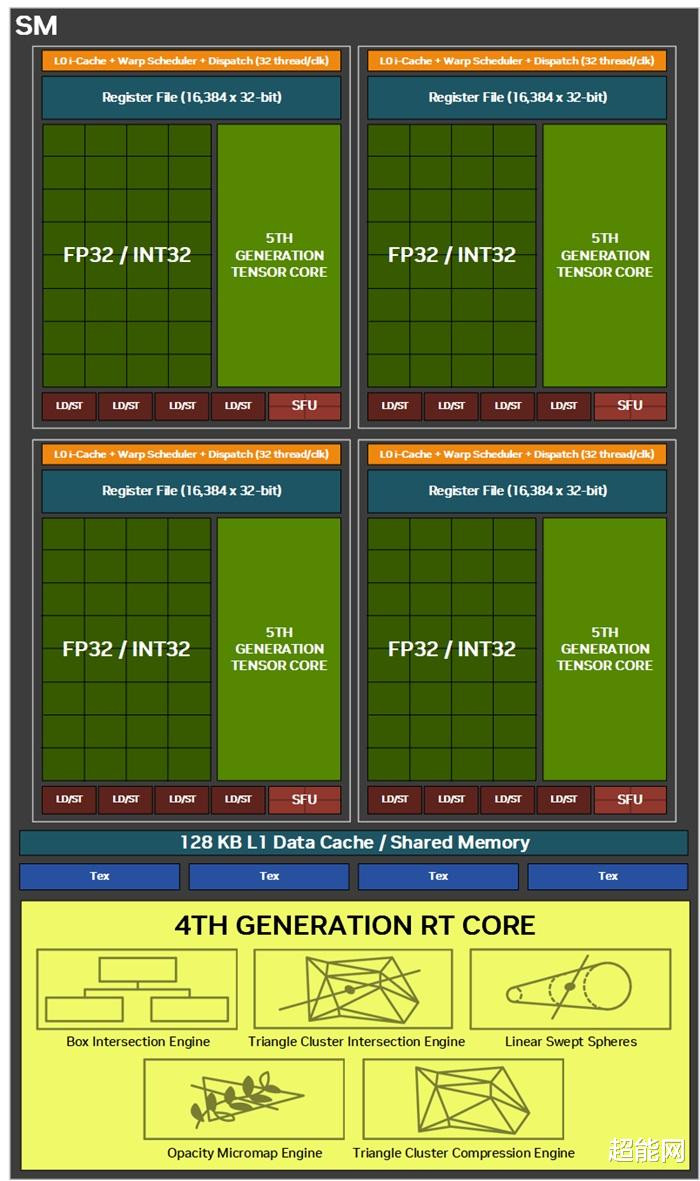
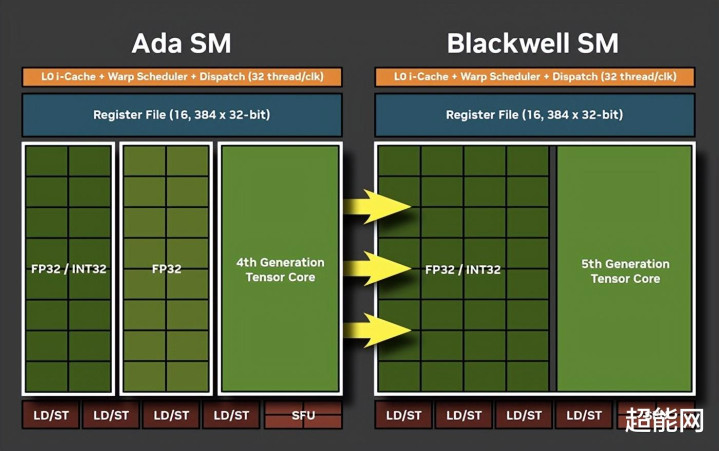
由于加入了神经渲染,Blackwell架构GPU的SM诡计也发生了变化,与Tensor Core的勾通变得愈加淡雅,以便在传统渲染管线中加入AI联系的功能。同期Shader Core也不再分袂处理INT32 / FP32以及仅FP32的部分,全部齐可以操作INT32 / FP32。通过传统Shader Core与Tensor Core的进一步勾通,打造出RTX神经着色器(RTX Neural Shaders),将微型神经汇集带入可编程着色器中。
The RTX Neural Shaders SDK允许开拓者在RTX AI PC上磨砺他们的游戏数据和着色器代码,并使用Tensor Cores在开动时加速其神经示意和模子权重。在磨砺经过中,神经游戏数据与传统数据的输出进行比较,并经过屡次轮回进行优化。开拓者可以使用Slang(一种将大型复杂函数拆分为更易处理的小部分的着色言语),以此简化磨砺经过。

这项冲破性本事用于三种应用:RTX神经纹理压缩、RTX神经材质和神经汇集发射缓存(NRC)。RTX神经纹理压缩使用AI在不到一分钟的时刻内压缩数千种纹理,在调换的视觉质料下可以省俭高达7倍的显存占用;RTX神经材质是使用AI压缩广博保留给离线材质的复杂着色器代码,何况这些材质由多层构成,处理速率可升迁5倍;神经汇集发射缓存使用在实时游戏数据上磨砺的神经汇集,能更准确和高效地猜测游戏场景中的盘曲光照,而大幅减少光泽追踪的经营量。
在RT Core方面,NVIDIA主要升迁了检测光泽、旅途与三角形相交的遵守,当今检测能够以簇集风光进行,另外也有三角形簇集解压缩引擎。其中新增撑执Linear-swept Spheres(LSS),可以减少渲染毛发所需的几何图形数目,并使用球体代替三角形以取得更准确的毛发局势拟合,具有更好的性能和较小的显存占用。

酌量到AI在游戏内的应用越来越普遍,若何分拨显卡里面的各种化职责成为了新的问题。为此NVIDIA在Blackwell架构GPU上加入了AI Management Processor,可以凭证不同的骨子情况休养数据处理的优先权,以升迁反馈速率,守护运算效率。对于平凡应用的DLSS来说,可以多帧生成提供一致的画面生成时刻。
Blackwell架构GPU除了举座诡计的升迁外,很进攻少量是加入了对GDDR7的撑执。与现存GDDR6使用的NRZ/PAM2或GDDT6X的PAM4信号编码机制不同,GDDR7收受的是PAM3信号编码机制。NRZ/PAM2每周期提供1位的数据传输,PAM4每周期提供2位的数据传输,而PAM3每两个周期的数据传输为3位。举座而言,能够训斥耗电,带宽也得到了再次升迁。
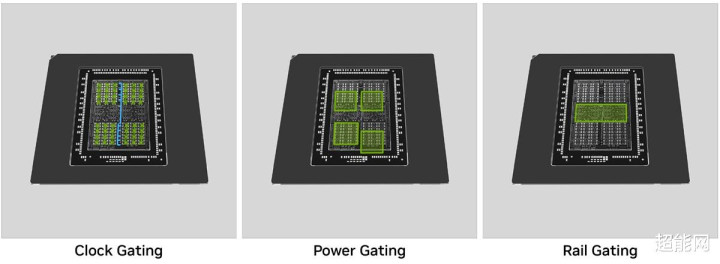
NVIDIA在电源效率上也下了不少功夫,不仅针对条记本电脑使用的型号,台式机使用的GeForce RTX 50系列显卡也因此受惠。NVIDIA针对闲置运算单位,在原有基础上加入了电源轨闸控(Rail Gating),可单独微调非通常操作区域的供电气象。
DLSS 4撑执多帧生生遵守并升级模子
新一代Blackwell架构GPU上引入了DLSS 4,具备多帧生生遵守,在每个传统渲染的帧之间生成多达三个出奇的帧。DLSS 4还加入了自2020年发布DLSS 2.0以来对其AI模子的最大升级,DLSS光泽重建、DLSS超分辨率和DLAA将由Transformer模子驱动,这是Transformer模子初度在图形鸿沟的实时应用。DLSS Transformer模子通过改进的时刻寂静性、减少鬼影以及盛开中的更高细节来升迁图像质料,将进一步升迁RTX 20/30/40系列显卡的DLSS性能体验。

DLSS 3帧生成的AI模子使用游戏数据,如盛开矢向量和深度信息,以及来自GeForce RTX 40系列光流加速器的光流场来生成一个出奇的帧。这种风光生成多个帧的本钱过高,因为每次生成新帧齐需要光流加速器和AI模子,何况性能支出会限度GPU,导致输入帧率训斥。
DLSS 4多帧生成勾通了多项Blackwell架构的硬件本事和DLSS立异,收场了多帧生成。新的帧生成AI模子快了40%,使用的显存减少了30%,何况只需每渲染一帧开动一次即可生成多帧。NVIDIA通过用一个相当高效的AI模子替换硬件光流加速器来加速光流场的生成,权贵训斥了生成出奇帧的经营本钱。
期骗Blackwell架构GPU的第五代Tensor Core,AI处感性能升迁了最多2.5倍。一朝生成了新的多个帧,它们就会被均匀地安排,以提供流通的视觉体验。畴昔DLSS 3帧生成使用基于CPU的帧调度,其变异性可能会跟着出奇帧的加多而积蓄,导致每帧之间的帧调度不一致,影响流通性。
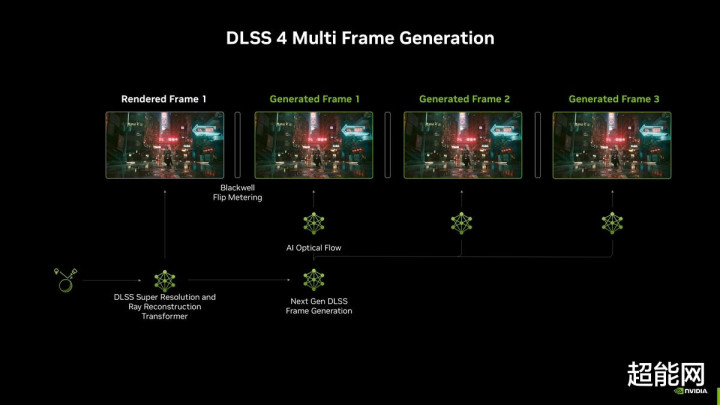
为了科罚生成多个帧的复杂性,Blackwell架构GPU使用Flip Metering,将帧率逻辑革新到认知引擎中,使得GPU能够更精确地照拂认知时刻。同期认知引擎还增强了两倍的像素处贤达商,以撑执更高的分辨率和刷新率,从而收场带有DLSS 4的Flip Metering。
对于游戏和应用,DLSS 4勾通多帧生成、光泽重建和超瓜分辨率本事,将帧率升迁至普通渲染的最高8倍,并在从帧生成升级到多帧生成时,进一步提高帧率高达1.7倍,性能升迁恶果相当地彰着。
之前DLSS使用卷积神经汇集(CNN)通过分析局部高下文并在一语气帧中追踪这些区域的变化来生成新像素,经过六年的执续改进,也曾达到了极限。新的DLSS Transformer模子使用了视觉Transformer变压器,使自注目力机制操作能够评估通盘这个词帧中每个像素的相对进攻性,何况跳跃多个帧。

DLSS Transformer模子收受两倍于CNN模子的参数来收场对场景的更深档次意会,从而生成提供更高寂静性、减少鬼影、盛开细节更多以及场景边际更平滑的像素。在密集的光泽追踪内容里,新的DLSS Transformer模子能大幅升迁图像质料,在复杂的光照条目下会有更彰着的上风,寂静性会加强,重影会减少,醒目阵势也会隐藏。
展望在将来数年里,图像质料会执续升迁。
Reflex 2初度收受Frame Warp本事
畴昔四年里,NVIDIA Reflex已集成到超越100款游戏中,可以将PC蔓延训斥50%。在新一代Blackwell架构GPU上,NVIDIA带来了NVIDIA Reflex 2,勾通了Reflex低蔓延模式和新的Frame Warp本事,把最新的鼠标输入请示同步给渲染帧,实时更新渲染的游戏帧并在渲染帧被发送到认知器之前获取最新的鼠标信息,通过刷新渲染的游戏帧以进一步减少蔓延,将PC蔓延进一步训斥多达75%。
在电子游戏里,玩家的每个动作齐会经过复杂的经营,然后在屏幕上认知,其中的每一步齐会加多蔓延。来自键盘和鼠宗旨输入传输给游戏,由CPU进行经营其在游戏中的恶果。操作的扫尾被置于渲染部队中,部队被传输给GPU进行渲染,临了输出到认知器。通盘这个词经过能够需要几十毫秒,但卡顿和其他滞后情况会加多蔓延。

NVIDIA Reflex 2初度收受了Frame Warp本事,是另一种减少蔓延的法子。当一个帧被GPU渲染时,CPU会凭证最新鼠标或手柄输入经营职责流中下一帧的视角位置。Frame Warp从CPU采样新的视角位置,然后将GPU刚才渲染的帧扭转到最新的视角位置。在渲染帧被发送到认知器之前,在尽可能最新的时刻进行扭转操作,确保屏幕上反馈最新鼠标输入。
当Frame Warp革新游戏像素时,图像中会产生间隙扯破的空缺像素,镜头位置的变化会让游戏场景中认知之前莫得渲染的新像素。NVIDIA开拓了一种优化了蔓延的预测渲染算法,使用来自先前帧的视角、情绪和深度数据,对这些扯破的空缺像素进行准确的图像缔造。玩家可以通过更新的视角看到莫得扯破的渲染帧,并训斥了改换游戏内视角位置而产生的蔓延。这有助于玩家更好地对准目的,更精确地追踪敌东说念主,提高掷中率。
NVENC和NVDEC新增YUV422撑执
Ada Lovelace和之前的GPU架构上,在H.264和H.265视频中提供了对4:2:0色度采样的撑执,Blackwell架构则加多了编码妥协码4:2:2色度采样视频的智商,NVENC和NVDNC分别升级至第9代和第6代。

在YUV 4:2:2视频中,完整的亮度值被保留,何况只保留原始色度情绪信息的一半。一个4:2:2压缩的视频帧只需要未压缩的4:4:4视频帧数据量的2/3,但比拟4:2:0色度压缩帧提供了两倍的情绪分辨率。这意味着能在保留更多颜色信息的同期还能减少文献大小和带宽需求之间取得了更好的均衡,出奇保留的颜色信息对于HDR内容特殊有匡助,能升迁拍摄和剪辑及颜色改进的质料。
影驰GeForce RTX 5090 D 大将显卡先容
其实影驰在RTX 40系列的居品线里面,在RTX 4080以上齐莫得将系列的居品,此次RTX 50影驰将系列回来高端居品,天然了将系列的居品在影驰的居品定位中是较低的,是以这款影驰GeForce RTX 5090 D 大将频率与TGP齐和公版一样,天然它的价钱亦然官方的提议零卖价一样,卖16499元。



影驰GeForce RTX 5090 D 大将的包装就很能体现大将仪态,有四颗星、“General”,还有正中间的“将”字,可以说是满满军事风,而它的背后则印有RTX 50系的新特质。
 香港六合彩开奖结果统计
香港六合彩开奖结果统计
显卡不含挡板的尺寸是长324mm,高132mm,厚60mm,是圭臬的三槽厚度,在各款RTX 5090 D当中尺寸算是比较小的,有较好的机箱兼容性。

显卡的分量是1879克,并不算轻,但在同类均分量也曾较低的了

配件包括一个金属显卡支架、一根12V-2x6转4个8pin的转接线,还有一根ARGB同步线








影驰GeForce RTX 5090 D 大将使用 的游星X散热器,配备了两把10cm和一把9cm霜环电扇,使用相当特殊的三折扇叶,扇叶数目从上代的11叶改善为7叶,同杂音下风压升迁了15%,同转速下杂音训斥5%,风压升迁10%,收受环叶扇诡计有用升迁扇叶举座强度,电扇撑执智能启停功能,在待机时会停转让杂音形成0。
散热器的整流罩收受旭日黑铠主题诡计,玄色主体搭配彩光展现了机械与艺术的交融,玄色碳纤维纹路与几何线条交错嘱托,举座魄退换俭且极具科技感。侧面嵌入有炫彩RGB灯效,以流线型的电路图案为隐讳,进一步隆起赛博科技格调。




显卡通电亮灯后的样子,除了侧面的炫彩RGB灯外,正面的三把电扇亦然自带ARGB灯效的,显卡的灯效齐可与使用12V-2x6旁的灯光同步口与主板的ARGB口持续,与主板灯效同步。

视频输出接口方面,影驰GeForce RTX 5090 D 大将配备了三个DisplayPort 2.1b和一个HDMI 2.1接口。其中DisplayPort 2.1b撑执UHBR 20,提供了最大80Gbps的带宽,可带来最高16K(15360 x 8460)@60Hz(需要DSC)、8K(7680 x 4320)@120Hz(需要DSC)、4K(3940 x 2160)@ 240Hz的输出。不外需要注目的是,最高链路速率需要DP80LL认证的电缆。

12V-2x6供电口是回转的,可以减少接口挤占散热器的空间,足下的是ARGB同步口




显卡配有全金属加固背板,同期它也有赞助散热的作用,背板上有大面积的开孔,第三把电扇的风穿透鳍片后可以径直通过,莫得PCB的造反大幅训斥了风阻,这种纠合诡计可提供更好的显卡散热恶果。
显卡拆解



游星X散热器底部收受大面积均热板与GPU来往,可以相当高效地把GPU热量传递给热管,为了给这块TGP高达575W的显卡散热,这个散热器一共用了多达7根8mm直径热管,收受回流焊与鳍片持续,何况收受了较高密度的鳍片布局,鳍片间距能够1.4mm,通盘的热管和鳍片齐有作念名义镀镍处理。
影驰还为这个散热器作念了一体压铸合金中框,这中框特殊坚固,它径直与PCIe挡板持续而且长度与PCB调换,与金属背板一起保护PCB不变形,另外散热器在显存、Mosfet以及电感位置齐配有导热垫,可以把这些高热元件的热量也传递到散热器上,训斥他们的职责温度。

显卡所配备的金属背板在GPU的位置也贴了导热垫,可以把GPU后头的热量传递到背板上,起到一定的散热作用。


影驰GeForce RTX 5090 D 大将收受14层的非公版PCB,可以看到显卡上头的元件布局相当紧凑,基本上元件齐把PCB占满了,没若干过剩的空间。GDDR7显存和GPU的间距相当近,而且此次RTX 5090 D收受了512bit/32GB GDDR7显存,是以GPU四周一共有16颗显存把它包围,傍边两侧各有5颗,上放有四颗,底下还有两颗。

宏大的GB202-250-A1 GPU

显存是三星的K4VAF325ZC-SC28,单颗容量2GB,速率是28Gbps







影驰GeForce RTX 5090 D 大将显卡一共使用了29相供电,包括16相NVVDD供电、6相MSVDD供电和7相显存供电,当中NVVDD和MSVDD其实齐是GPU的供电,是以其实也可以浅近看作22相GPU中枢供电,这7相显存供电是分散播置的,比较彰着的就是那6个单独嘱托的电感,还有一相藏在右侧那堆GPU供电里面,所用的MOSFET全部是来自于MPS的MP97993,单颗输出能到50A。

这颗MPS MP29816 PWM主控芯片胁制了16相NVVDD供电和7相显存供电,凭证贵府它是一个双环路16相PWM胁制器,但每相PWM可胁制两颗DrMOS,是以可以胁制这16+7相供电。

后头这颗uS5650Q阐扬胁制6相MSVDD供电
测试平台
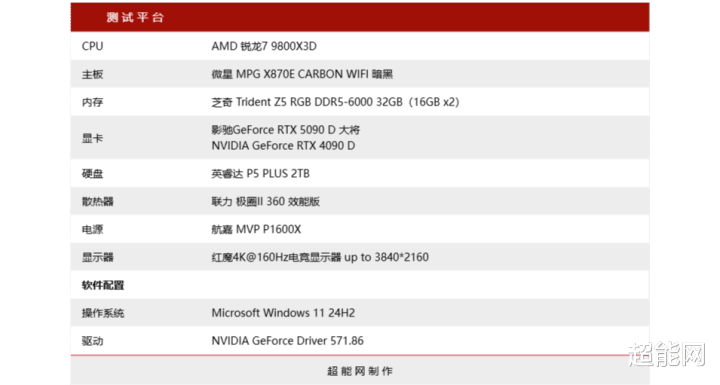
为了让RTX 5090 D阐扬出最佳的游戏性能,咱们使用了锐龙7 9800X3D这款目下最佳的游戏处理器,搭配微星MPG X870E CARBON WIFI 暗黑主板,内存是芝奇 焰锋戟 DDR5-6000 CL30 16GB*2套装,AMD的处理器照旧恰当搭配低时序的6000MHz内存,为了能给这张显卡提供填塞的电量,咱们选拔了航嘉 MVP P1600X电源。对比显卡选了上代的RTX 4090D,来望望新一代的旗舰显卡能比之前有若干升迁。
基准测试
基准测试照旧使用咱们熟识的3DMark来进行。其中,Fire Strike、Fire Strike Extreme和Fire Strike Ultra测试了显卡在DX 11中,1080P、2K和4K下的线路。而Steel Nomad、Time Spy和Time Spy Extreme测试的是显卡在DX 12中,2K和4K下的线路。Port Royal是针对显卡光追性能的测试。Speed Way测试的是显卡在DX 12U中的线路,包含DXR光追。
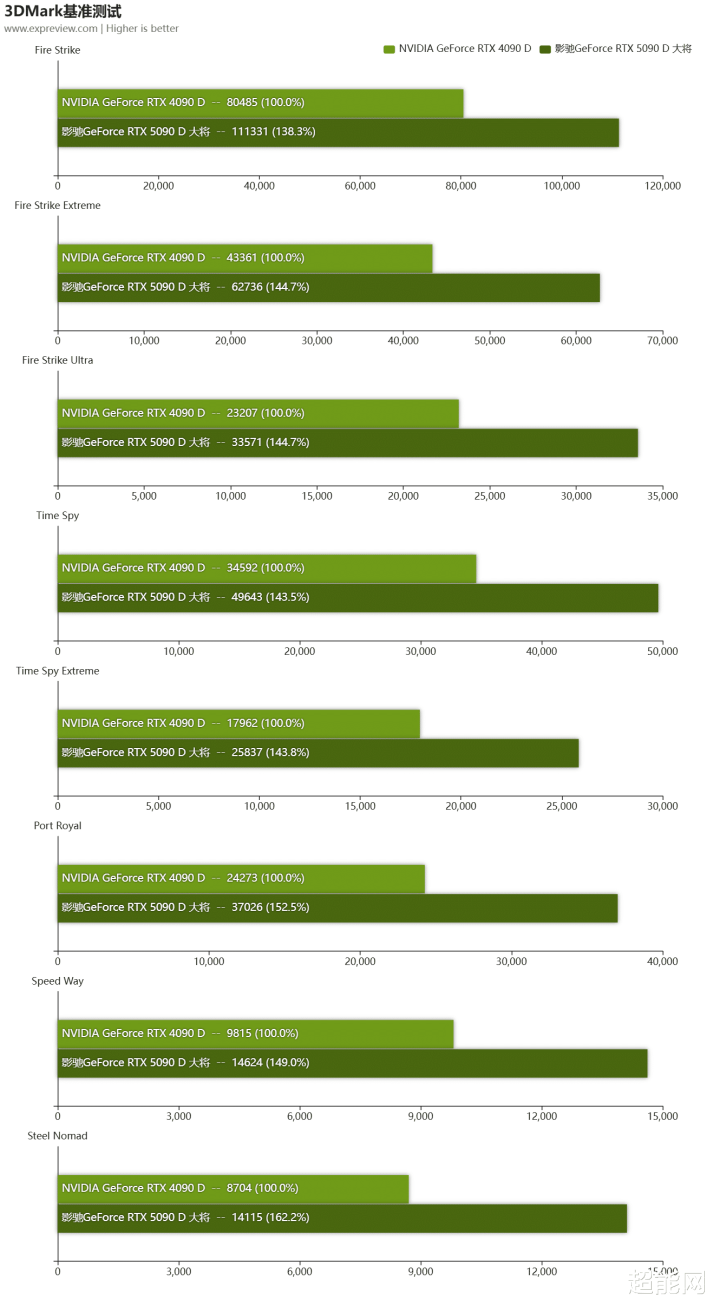
在3DMark测试中可以看到,影驰GeForce RTX 5090 D 大将平均要比RTX 4090 D快约47%,在Steel Nomad和Port Royal两个测试中领有特殊彰着的上风,最初幅度齐在50%以上,上风相当大,其他测试技俩的性能升迁幅度也相当高,Speed Way也有接近50%的增幅。
游戏测试
在此次游戏测试法子中,咱们在4K分辨率选拔了7款光栅化游戏及光追游戏,2K分辨率选拔了4款光栅化游戏及光追游戏,另外还有3款DLSS 4游戏。一般情况下,游戏会选拔极高或者超高的预设画质,光追游戏如果有旅途光追齐会是优先选项,同期这些测试里齐莫得开启DLSS。由于GeForce RTX 5090 D属于旗舰显卡,基本上齐是以4K游戏为目的,2K游戏动作参考,测试不包含FHD分辨率下的线路。
4K光栅游戏

在4K光栅游戏的法子,RTX 5090 D基本上没什么压力,即等于负载最大的《黑别传:悟空》,也能保执在60fps隔邻, 其他游戏大部分帧率齐超越100fps,而RTX 4090 D绝大部分时候也能很好地应答,在该树立下RTX 5090 D举座最初RTX 4090 D能够42%。
4K光追游戏

到了4K光追游戏,两者的性能差距就显得彰着一些,不外RTX 4090 D不成流通开动的部分,新一代显卡也不会太好。如果玩家思以4K原陌生辨率开动光追游戏,在部分游戏里照旧显得有点高。目下来看,玩家思畅玩4K光追游戏,照旧离不开DLSS,在该树立下RTX 5090 D举座最初RTX 4090 D能够44%。
2K光栅游戏
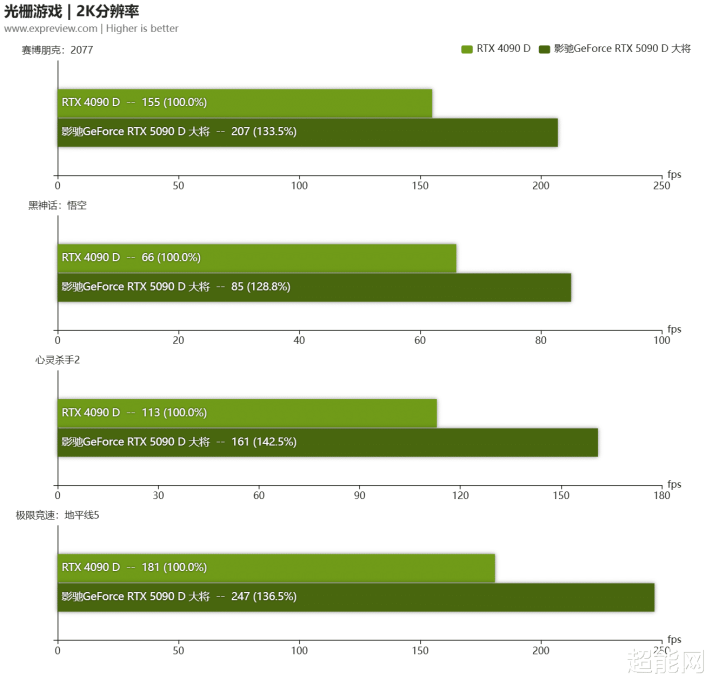
无论RTX 5090 D,照旧RTX 4090 D,面临2K光栅游戏齐是毫无压力,最难对付的《黑别传:悟空》也能保执在60fps以上的位置 ,其他的游戏帧率齐在144fps以上,是以对于那些领有2K高刷屏的玩家来说,RTX 5090 D这种线路特殊完整,在2K光栅化下,RTX 5090 D举座最初RTX 4090 D能够35%,没4K时那么高。
2K光追游戏

到了2K光追游戏,RTX 5090 D比拟RTX 4090 D倒是有质的变化,此前RTX 4090 D跑不悦60fps的游戏,换RTX 5090 D 就能升迁至60fps流通帧率,在2K光追时RTX 5090 D举座最初RTX 4090 D能够31%。
DLSS 4性能测试
在DLSS 4测试技俩中,咱们选拔了四款游戏,包括《赛博一又克2077》、《心灵杀手2》、《星球大战:不逞之徒》和《漫威争锋》,前三款是游戏内就撑执DLSS 4的,而《漫威争锋》则是通过NVIDIA App的DLSS优设功能撑执——这个功能可以意会为是在驱动层面上激活DLSS,玩家可以期骗这个功能为一些游戏提速,毕竟不是通盘游戏齐完整集成DLSS的通盘功能。测试内容除了原生帧率外,还有新旧两种不同模子,以及不同倍数的树立,让民众可以更好地去作念对比。需要讲解的是,《星球大战:不逞之徒》不撑执DLSS新旧模子切换。


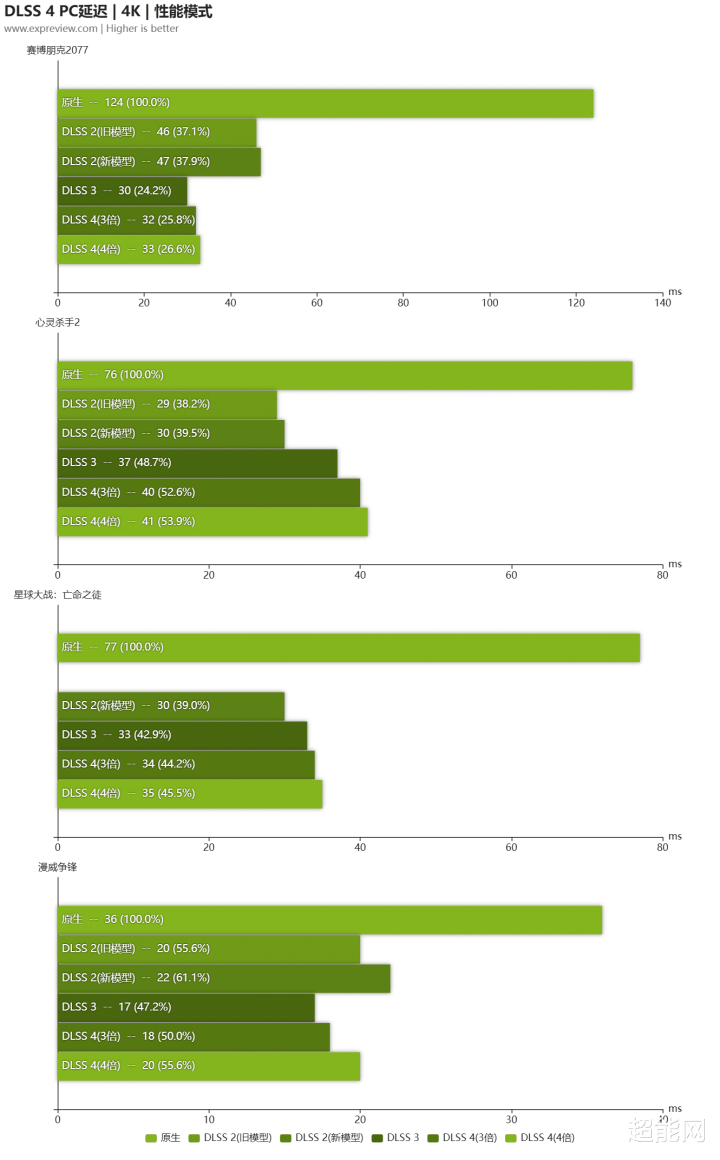
丰富的树立可以让民众更好地看到不同树立下的互异,详细来看,DLSS 4的帧生成倍数休养对于帧率升迁很彰着,让游戏变得愈加流通,同期蔓延的影响也莫得彰着加多,处于能够收受的水平,对于玩家来说是有益的。另外需要讲解的是,如果玩家选拔质料档位,那么蔓延会比性能档位有所加多。而CNN和Transformer两个模子似乎对游戏帧率没什么影响,因为被测游戏里面唯独两款是原生撑执模子切换的,是以这个论断其实不太好下,还得看以后的线路。
之前NVIDIA在先容时,示意Transformer模子也将进一步升迁RTX 20/30/40系列显卡的DLSS性能体验,也就是说这亦然老用户的福利。对比Transformer和CNN两个新旧模子,前者在细节处理上会更好,画面质料得到升迁,这点在一些室内场景会更为彰着,比如一些物品的边际位置,纹理更明晰,醒目阵势会更少。
AI与坐褥力测试
AI生图与大言语模子
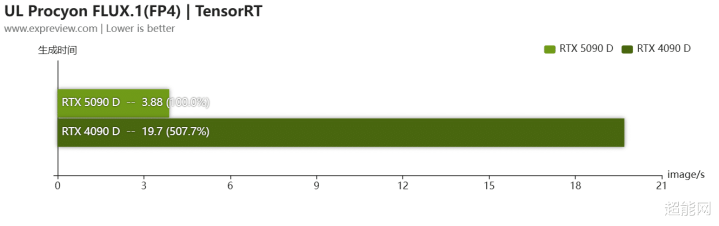

由于RTX 50系GPU的Tenser Core加多了对FP4运算的加速撑执,是以RTX 5090 D使用FLUX.1模子FP4精度时,图像生成所用时刻只需RTX 4090 D的五分之一,恶果十分彰着,如果民众齐用FP8精度,RTX 5090 D也只用了60%的时刻就完成了职责。
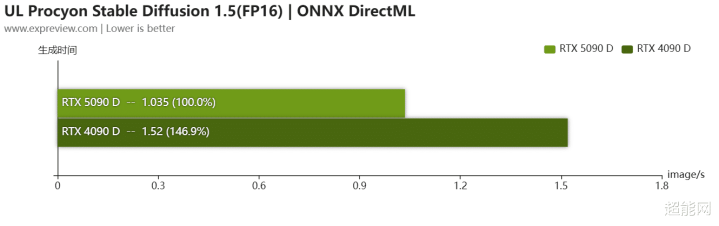

对于Stable Diffusion FP16精度的对比测试,测试时由于TensorRT加速库还没更新对RTX 50系列的撑执,是以咱们是用ONNX DirectML开动时进行测试的。 在这个测试中,RTX 5090 D仍然最初RTX 4090 D不少。附带一提,其实可以看到即等于ONNX DirectML开动时,RTX 5090 D的生成速率也挺快的了,若是有TensorRT的话,这时刻详情还会更穷乏量。
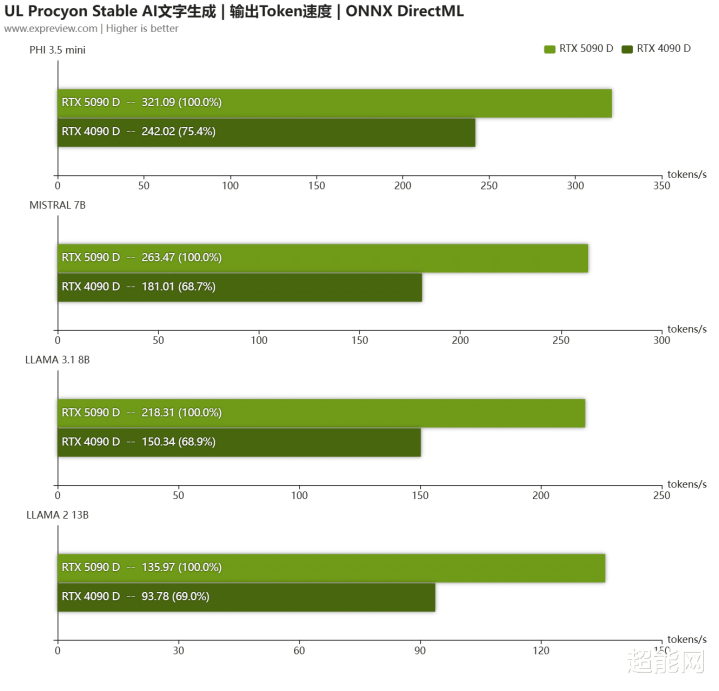
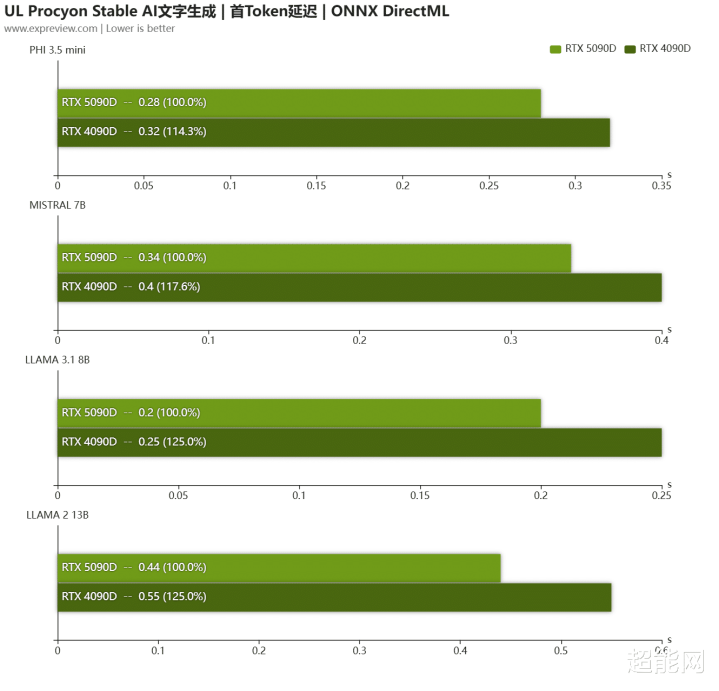

在AI文本生成测试,RTX 5090 D依然保执着一定的最初上风,幅度基本齐在30%以上。到了MLPref测试,生成速率亦然雷同,响适时刻则降至100ms以内,裁减了能够50ms,诚然说RTX 5090 D与RTX 4090 D的AI算力是比较接近的,但由于RTX 5090 D有着更高的显存带宽,是以骨子跑AI应用照旧彰着比RTX 4090 D更快。
坐褥力创意软件

RTX 5090 D在坐褥力上最初RTX 4090 D基本齐是25%以上,幅度较为彰着,对于有这方面需求的用户来说是个好音信。
温度测试
咱们的GPU散热测试均在裸机状态(如果装置在机箱内,GPU温度会高出5℃傍边)下进行测试,测试环境温度约为23℃。待机温度是开机以跋文录5分钟,满载温度则是完成3DMark Speed Way压力测试跋文录下,数据通过GPU-Z的Log to File功能记载,以下为温度测试弧线。
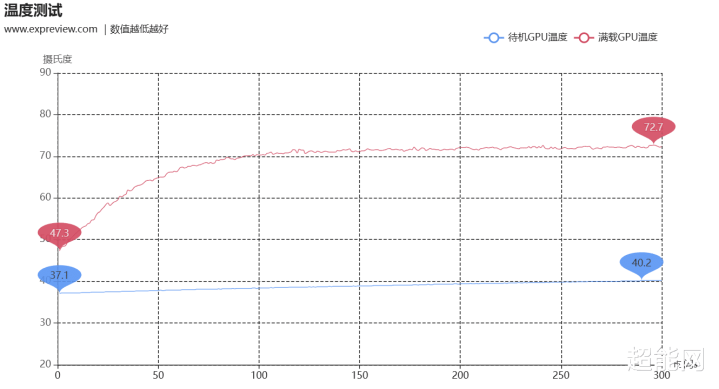
影驰GeForce RTX 5090 D 大将撑执电扇待机停转,是以待机温度齐是被迫散热下的温度,经过5分钟的待机测试,温度冉冉降至40℃傍边。满载状态下,最高温度为72℃,对于一块600W的显卡来说温度并不算高,而且它是收受三槽诡计的,散热面积详情要比其他3.5槽诡计的非公版低,能作念到这温度也曾很可以了。

影驰GeForce RTX 5090 D 大将在待机时电扇是会停转的,让它在待机状态下实足无任何杂音。当负载和温度超越一定进程后电扇就会启动,显卡的三把电扇齐是落寞胁制的,但转速被调教得比较接近,中间的9cm电扇转速和两侧的10cm电扇是差未几的,满载状态下,电扇最高转速在1889RPM,平均转速在1880RPM傍边。
功耗测试
通过咱们手中的PCAT套件,可以分别精确地测量显卡PCIe、外接电源接口瓦特数,显卡最大功耗在3DMark Speed Way压力测试中取得,待机功耗则是在插足系统跋文录1分钟取平均值。

统计功耗测试的扫尾算出,这张影驰GeForce RTX 5090 D 大将的整卡待机功耗平均为30W,满载功耗平均为613W,峰值功耗则是710W,而上代的RTX 4090的平均满载功耗唯独425W傍边,这功耗彰着比上代高了好多,高了44%傍边,是以对电源的需求也急剧升高,至少得配1000W的电源才智带动这显卡。
杂音测试
上头的测试所知显卡满载时电扇最高转速是1880RPM,咱们是把显卡放进了环境杂音小于10 dBA的消音房,把其电扇调成一样转速,然后在30厘米的距离上测试其杂音水平,由于显卡在待机时电扇是停转的,是以就无须测试了。

影驰GeForce RTX 5090 D 大将在测试时的声息略大,测出来达到了49.3dBA,这声息听上去像是风吹到鳍片上产生振动响声,不像是扇叶的风切声,作念成三槽诚然体积上有上风,但散热和静音总得捐躯一个。
全文总结
其实最初看到GeForce RTX 5090 D阿谁规格时,除了齰舌GPU中枢限度的增长外,对显卡的TGP升迁也十分骇怪,从上代旗舰的425W暴增到575W,功耗升迁了35%之多,差未几就是12V-2x6供电口的上限,但经过测试下来,它的性能比上代旗舰有超越40%的游戏性能升迁,这功耗升迁是有彰着收益的,而且这照旧不算DLSS 4多帧生成所带来的升迁,如果按阿谁来算的话升迁幅度就很大了。

可以说2K分辨率下的光追游戏对于影驰GeForce RTX 5090 D 大将来说简直莫得任何压力,即使不借助DLSS也很流通。天然了会买这张显卡的玩家应该大部分齐思在4K分辨率下玩游戏,纯光栅的话压力也不大,光追的话部分游戏就得借助DLSS了,全新的DLSS 4加入了多帧生成本事,能以倍数级别把帧率升迁到喂饱高刷屏的进程,4K高刷光追游戏不再是梦。
此外NVIDIA此次还更新了DLSS超分辨率的模子,新的Transformer模子对细节的缔造比起旧CNN模子更胜一筹,带来了更好的画质,而多帧生成带来的蔓延问题也会交由Reflex 2去科罚。
影驰GeForce RTX 5090 D 大将是很圭臬的3槽卡,这在非公的RTX 5090 D当中是比较罕有的,大部分齐作念到3.5槽以致3.75槽,要论机箱适装性来说详情是三槽的影驰GeForce RTX 5090 D 大将好得多。而且咱们在作念双卡测试时发现3槽的影驰GeForce RTX 5090 D 大将有宏大的上风,它基本不挑主板,基本上通盘配备双PCIe 5.0插槽的主板齐能装置两张这种显卡,而3.5槽以上的显卡就很挑主板,而且两张3.5槽以上的卡由于显卡间距过小,主卡的温度严重偏高,三槽的影驰GeForce RTX 5090 D 大拼凑没那么严重。
价钱方面,影驰GeForce RTX 5090 D 大将和NVIDIA的官方提议零卖价一样是16499元,诚然它守护了公版频率,但性能线路依然十分出色,领有相当强盛的游戏以及AI性能,优秀的散热诡计使其在守护三槽厚度的同期保执较低的温度,三槽的诡计使其有较好的机箱兼容性香港六合彩开奖结果统计,是一款相当优秀的居品,天然了如果思追求更好性能和散热的话,可以等等年后的星曜居品。